在Java程序和Lucene中使用中科院分词系统ICTCLAS
分词是文本处理、分析的基础,中科院分词系统ICTCLAS是中文领域中功能强大的分词系统。下面介绍如何在一般的Java程序和Lucene中使用ICTCLAS。
首先在ICTCLAS官方网站下载分词系统源码,地址是http://ictclas.org/ictclas_download.aspx,目前的版本如下图所示:
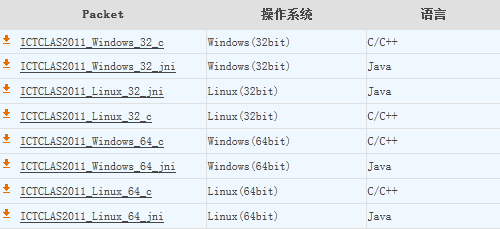
根据操作系统和编程语言的需要选择下载,本文使用的是ICTCLAS2011_Windows_32_jni版本。
将下载文件解压后,有四个文件夹:
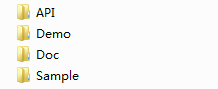
其中,API中是完整的软件包,可以调用其中的函数实现分词功能;Demo是使用图形化界面演示分词效果的程序;Doc是软件文档;Sample是一个Java中调用ICTCLAS的例子。
1.一般Java程序
一般Java程序使用中科院分词系统ICTCLAS参考Sample文件夹中的示例程序即可。
示例程序TestMain.java的主要内容如下:
[code lang=”java”]class TestMain { //主函数 public static void main(String[] args) { try { //字符串分词 String sInput = "随后温总理就离开了舟曲县城,预计温总理今天下午就回到北京。以上就是今天上午的最新动态"; testICTCLAS_ParagraphProcess(sInput);//同testimportuserdict和testSetPOSmap } catch (Exception ex) { } }
public static void testICTCLAS_ParagraphProcess(String sInput)
{
try
{
ICTCLAS50 testICTCLAS50 = new ICTCLAS50();
String argu = ".";
//初始化
if (testICTCLAS50.ICTCLAS_Init(argu.getBytes("GB2312")) == false)
{
System.out.println("Init Fail!");
return;
}
//设置词性标注集(0 计算所二级标注集,1 计算所一级标注集,2 北大二级标注集,3 北大一级标注集)
testICTCLAS50.ICTCLAS_SetPOSmap(2);
//导入用户词典前分词
byte nativeBytes[] = testICTCLAS50.ICTCLAS_ParagraphProcess(sInput.getBytes("GB2312"), 0, 1);//分词处理
System.out.println(nativeBytes.length);
String nativeStr = new String(nativeBytes, 0, nativeBytes.length, "GB2312");
System.out.println("未导入用户词典的分词结果: " + nativeStr);//打印结果
//导入用户字典
int nCount = 0;
String usrdir = "userdict.txt"; //用户字典路径
byte[] usrdirb = usrdir.getBytes();//将string转化为byte类型
//导入用户字典,返回导入用户词语个数第一个参数为用户字典路径,第二个参数为用户字典的编码类型
nCount = testICTCLAS50.ICTCLAS_ImportUserDictFile(usrdirb, 0);
System.out.println("导入用户词个数" + nCount);
nCount = 0;
//导入用户字典后再分词
byte nativeBytes1[] = testICTCLAS50.ICTCLAS_ParagraphProcess(sInput.getBytes("GB2312"), 2, 0);
System.out.println(nativeBytes1.length);
String nativeStr1 = new String(nativeBytes1, 0, nativeBytes1.length, "GB2312");
System.out.println("导入用户词典后的分词结果: " + nativeStr1);
//保存用户字典
testICTCLAS50.ICTCLAS_SaveTheUsrDic();
//释放分词组件资源
testICTCLAS50.ICTCLAS_Exit();
}
catch (Exception ex)
{
}
} } [/code]
编译、运行此程序,分词结果如下。

其中,分词的词性标注是可选的,词性标注的含义在Doc目录下的文档中有详细说明。
2.Lucene
在Lucene中起到文本分析作用的类是Analyzer,Lucene中自带的不同Analyzer子类具有不同的分词功能。在较新的Lucene版本中(我使用的是3.0.3),Lucene自带的smartChineseAnalyzer是基于中科院分词系统实现的,中文分词效果比较好,已经能满足一般的中文分词需要。但是它不具备ICTCLAS原有的词性标注功能,如果想使用ICTCLAS的完整功能,则需要基于ICTCLAS编写自己的Analyzer子类。
ICTCLAS官网上有一个编写Analyzer子类的程序示例,地址如下:
另外,我的同学cjy写了一个更为完整的Analyzer子类,可以参考,源代码下载地址为:
将中科院分词系统ICTCLAS应用到Lucene中的Analyzer源代码
