并查集笔记
最近在读另一本经典的算法教材:Algorithms(4th edition, Robert Sedgewick and Kevin Wayne),相比其他算法教材,这本书有几个特点:
1.图示非常丰富,阅读起来更有趣,更易懂;
2.给出了测试算法用的不同规模的数据和测试方法,以及展示算法结果所需要的工具。这些工具使得算法的测试、结果展示非常方便、直观。
3.介绍问题时更自然,相比算法导论定义、证明的方式,本书给出算法的应用场景,对需要解决的问题,不断改进算法得到最优结果,逐步改进的思路符合人们研究问题的正常过程,思维不跳跃,使学习过程有逻辑可循。
这本书有一个配套网站,http://algs4.cs.princeton.edu/home/,网站上除了提供书的部分内容,程序和数据下载外,还提供了课程的幻灯片和一些算法过程展示视频,效果非常赞。
下面是我对书中1.5节Case Study:Union-Find一节所做的笔记,可以部分反映出这本书的特点。
</br>
问题引入:动态连通性(Dynamic connectivity)
输入是一系列整数对,其中每个整数代表某种类型的对象,我们将整数对p q的含义解释为“p和q连通”。连通是一种等价关系,即满足:
自反性:p和p连通;
对称性:如果p和q连通,那么q和p连通;
传递性:如果p和q连通,q和r连通,那么p和r连通。
等价关系将所有对象分成等价类:如果两个对象连通,则它们属于同一个等价类。
我们的目标是:用程序过滤掉输入序列中不连通的数对。换句话说,当程序读入一对数p q时,只有当根据已经读取的所有数对不能说明p q连通时,才将p q数对输出,否则如果能判断出p q连通,则忽略p q数对,继续读下一对数。
用下图说明问题,图中有10个点,左侧数字为每次读入的连通数对。红色边为根据最新读入的数对产生的新边(即此时应输出这个数对),注意第二幅图当输入8 9时,由于8 9已经连接,因此不在8 9节点中增加新边(即不输出8 9数对)。连通完成后,图中左侧的三列点和右侧两列点分别为等价类。
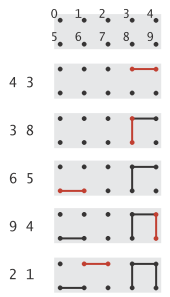
上面描述的动态连通性问题在几个领域有许多应用,如在网络中:
1.输入的整数代表网络中的计算机,数对代表网络中的连接。我们的程序用来判断为了让p和q通信,是建立一个新的直接连接,还是可以用已有的连接建立通信路径;
2.整数代表电子电路中的连接点,数对代表连接各点的线路;
3.整数代表社交网络中的人,数对代表好友关系。
在这些应用中我们可能需要处理数百万的对象和数十亿的连通关系。
术语
为了便于讨论,用网络术语定义问题。我们称上面的对象为点,称数对为连接,称等价类为连通组件,简称组件。简单起见,假设我们有N个点,每个点用整数命名,从0到N-1。
下图是一个规模大一些的连通性问题实例,从中可以看出连通性问题的困难之处。

图中有625个点,很容易看出左下角的5个点是一个组件,但是并不容易判断任意两点的连通情况。对程序来说任务难度可能更大,因为程序只能处理点的名字和连接,并不能获得图标的几何结构。怎样才能快速判断给定的两个点是否连通呢?
问题精确定义(API)
为了解决问题,第一步工作是给出问题精确的定义。通常我们对一个算法的需求越多,用来实现它的时间和空间就越多,困难也越大。因此需要给出适当的定义。
为了定义问题,用一套API来封装所需要的基本操作:初始化;为两个点增加链接;标识包含一个点的组件;判断两个点是否属于同一组件;给组件计数。我们得到以下API:
[code lang=”java”] //Union-find API public class UF UF(int N) //initialize N sites with integer names (0 to N-1) void union(int p, int q) //add connection between p and q int find(int p) //component identifier for p (0 to N-1) boolean connected(int p, int q) //return true if p and q are in the same component int count()// number of components [/code]
定义API使得实现一个解决动态连通性问题的算法简化成了实现上述API。
用数组id[]记录每个点所属的组件,一般用一个组件中的某个点作为组件的标识符。初始时,每个点为一个组件,所以对i从0到N-1将id[i]置为i。
并查集API的基本实现如下,算法维护两个实例变量:组件的数目和数组id[]。不同的算法区别在于find()和union()的实现。
[code lang=”java”] public class UF{ private int[] id; //组件标识数组 private int count; //组件数量
public UF(int N){
id = new int[N];
for(int i = 0; i < N; i++)
id[i] = i;
count = N;
}
public void union(int p, int q){}
public int find(int p){}
public boolean connected(int p, int q){
return find(p) == find(q);
}
public int count(){
return count;
}
public static void main(String[] args){
int N = StdIn.readInt();
UF uf = new UF(N);
while(!StdIn.isEmpty()){
int p = StdIn.readInt();
int q = StdIn.readInt();
if(uf.connected(p, q)) continue;
uf.union(p, q);
Stdout.println(p + " " + q);
}
} } [/code]
测试方法
UF类中提供了供测试用的main方法,它读取输入的整数对,如果数对没有连通,就将其连通并输出此数对。
提供了3个不同大小的测试数据集:tinyUF.txt包含10个点的11个连接,mediumUF.txt包含625个点的900个连接,largeUF.txt包含100万个点的200万个连接。数据的形式为:
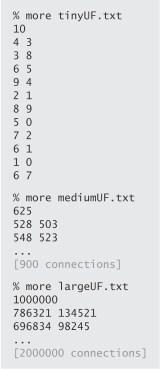
每个数据第一行为总点数,剩下各行是各个连通的数对。
算法分析方法
为了分析算法,关注每个算法访问(读或写)数组元素的次数。
算法实现
下面给出三种算法实现,并逐渐提高性能。
(一)Quick-find
第一种方法维持的不变式是:当且仅当id[p]和id[q]相同时,p和q才是连通的。即同一个组件中的点有相同id[]值。这一方法称为quick-find,因为find(p)只返回id[p],一次访问id[]即可完成。为了维持此不变式,操作union(p, q)时,首先检查p,q是否属于同一组件,如果不属于,则修改p、q组件中点的id[],使所有id[]项相同。例如:

上图中,p=5,q=9,p和q原本属于不同组件,将它们连通时,将p所在组件的标识改为8,使得连个组件标识一致,成为同一组件。
算法实现
[code lang=”java”] pubic int find(int p){ return id[p]; }
public void union(int q){ int pID = find(p); int qId = find(q); if(pID == qID) return; for(int i = 0; i < id.length; i++){ if(id[i] == pID) id[i] = qID; } count–; } [/code]
性能分析:
find()操作很快,因为每次操作只访问id[]一次。但是union()操作每次都需要遍历id[]一遍,因此quick-find算法对大数据量问题不适用。
quick-find算法每次find()操作需一次数组访问,每次union()需要N+3到2N+1次数组访问(每次union(),需要两次find(),测试id[]中所有项,并更改其中1到N-1个项)。
考虑一个动态连通性问题最终得到一个单个组件,需要至少N-1次union(),即至少$$(N+3)(N-1)\sim N^2$$次数组访问,即quick-find是平方阶时间复杂度的算法。对大数据量,如largeUF.txt,quick-find无法解决问题,因此需要更好的算法。
(二)Quick-union
下一个算法考虑加速union()操作,它使用和前一个算法相同的数据结构id[],但是对id[]的值有不同用法:每个点的id[]项是该点所在的组件中另一个点的名称(可以是该点自己的名字),称这样的连通为链接(link)。
为了实现find(),从给定点开始,沿着它的链接到另一个点,再沿着这个点的链接到又一个点,这样一直继续直到到达根节点,即一个链接到自己的点。
这个算法的不变式是:当且仅当两个点的find()过程到达同一个根,这两个点属于同一个组件。
为了维持此不变式,union(p, q)操作沿着链接分别找到p和q的根,然后通过将其中一个根链接到另一个根,使得其中一个组件重命名,两个组件合成一个,这一算法称为quick-union。在合并根节点时,任意选择是重命名包含p的组件或是包含q的组件。
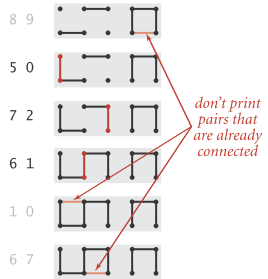
下图显示了以tinyUF.txt作为测试数据时,quick-union的执行过程:
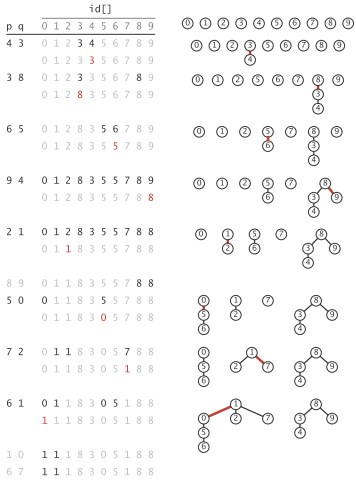
quick-union算法的id[]实际上实现了树的森林表示,id[]项是指向父节点的链接,根节点有指向自身的链接。森林中的每棵树是一个组件,根为该组件的标识。
算法实现
[code lang=”java”] pubic int find(int p){ while(id[p] != p) p = id[p]; return p; } public void union(int q){ int pRoot = find(p); int qRoot = find(q); if(pRoot == qRoot) return; id[pRoot] = qRoot; count–; } [/code]
性能分析
quick-union似乎比quick-find快速,因为对每个输入数对,它不需要遍历整个数组,但是具体快了多少?在最优情况下,find()只需要一次数组访问获得组件标识;最坏情况下,find()需要2N+1次数组访问。具体性能依赖于输入的情况。我们在此不进行quick-find和quick-union的比较分析,因为接下来会研究一个更好的算法。在此可以认为,quick-uinon比quick-find有所提高,因为quick-find的union操作总需要线性时间,而quick-union并不总需要(取决于输入)。
find()操作的数组访问为1加上当前点的2倍深度;union()和connected()的数组访问次数是两个find()操作(如两个点属于不同树,union操作需要再加1)。
考虑quick-union的最坏情况,一个最终合为一个组件的动态连通性问题,输入数对的依次是0-1,0-2,0-3等等,N-1个这样的数对后,我们得到N个点组成的一个组件。由quick-uion生成的树高度是N-1,从叶子到根,依次是0,1,...N-1,对0 i数对的union()操作,数组访问次数是2i+2,因此对N-1个数对,数组访问总次数为$$N^2$$阶。
(三)Weighted quick-union
通过简单修改quick-union算法,可以保证quick-union算法的最坏情况不会发生。和quick-union任意的选择第二课树连到第一棵树不同,通过记录每棵树的大小,每次将较小的树连到较大的树上。这个算法称为加权(weighted)quick-union。
下图说明quick-union和weighted quick-union的区别:
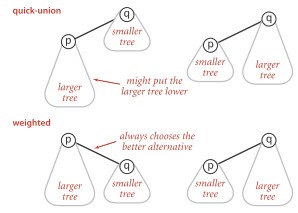
上图可以看出:quick-union的连通策略使得生成的树趋于不平衡,进而使find操作所需时间越来越长;而weighted quick-union 总将小树连向大树,树的平衡性更优,避免性能恶化。
算法实现
[code lang=”java”] public class WeightedQuickUnionUF { private int[] id; private int[] sz; private int count;
public WeightedQuickUnionUF(int N){
count = N;
id = new int[N];
sz = new int[N];
for(int i = 0; i < N; i++){
id[i] = i;
sz[i] = 1;
}
}
public int count(){
return count;
}
public boolean connected(int p, int q){
return find(p) == find(q);
}
private int find(int p){
while(p != id[p]) p = id[p];
return p;
}
public void union(int p , int q){
int i = find(p);
int j = find(q);
if(i == j) return;
if(sz[i] < sz[j]){
id[i] = j;
sz[j] += sz[i];
}
else{
id[j] = i;
sz[i] += sz[j];
}
count--;
} } [/code]
性能分析
命题:由weighted quick-union生成的N个点组成的森林中,任意一点的深度最大为logN。(证明:略,见原书p229)。
推论:对N个点采用weighted quick-union算法,find(),connected()和union()的最坏情况时间复杂度是logN.
下图展示了对100个点规模的动态连通性问题,经过88次union()操作后,quick-union和weighted quick-union的对比:
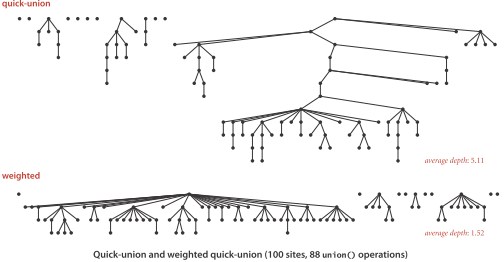
从中可以看出,加权后的算法,森林中树的高度明显更低,只有很少的点离树的根较远。
三种算法性能对比
| 算法 | union | find |
| quick-find | N | 1 |
| quick-union | tree height | tree height |
| weighted quick-union | lgN | lgN |
| impossible | 1 | 1 |
总结
Algorithms一书更容易让人体会到学习、使用算法的快乐之处。如果你在《算法导论》的数学证明中有些疲倦时,不妨找来这本书,重拾初学者的乐趣。
Published:
12 May 2012


windows下使用makefile示例
一、环境准备
1.安装MinGW 2.修改环境变量,把%MinGW%/bin添加到path中(%MinGW%为MinGW安装路径) 3.把%MinGW%/bin中的mingw32-make.exe复制,并重命名为make 验证上面三步是否成功: 在cmd窗口中输入,make -v,如果输出make版本信息则安装正确。
二、makefile测试 1.在准备测试的路径(如 C:\Users\James\test)下新建如下两个代码文件: [code lang=”c”]//—————————main.c : —————————// #include "stdio.h" main() { func(); printf("this is main\n"); getch(); }[/code]
[code lang=”c”]//—————————func.c : —————————// #include "stdio.h" func() { printf("this is func\n"); getch(); }[/code]
2.新建makefile文件: [code lang=”c”] test:main.o func.o gcc -o test main.o func.o func.o:func.c gcc -c func.c main.o:main.c gcc -c main.c [/code]
注意:上面的gcc -o和gcc -c前面必须是TAB,不是空格,否则运行make时会报错:“makefile:2: *** missing separator. Stop.”。
3.在cmd中切换至当前路径(C:\Users\James\test)下,运行make命令,输入: make 回车。 make命令执行的结果为: [code lang=”c”]C:\Users\James\test>make gcc -c main.c gcc -c func.c gcc -o test main.o func.o[/code]
此时路径下已经编译生成了test.exe,输入test即可看到运行结果。
本文主要参考了[1],windows下的各版本gcc介绍可以参考[2],makefile入门可以参考陈皓的《跟我一起写 Makefile》[3].
参考资料 [1]windows下使用makefile编译C语言: http://blog.csdn.net/zhanghan3/article/details/1334308 [2]gcc for Windows开发环境介绍, http://blog.csdn.net/Mobidogs/article/details/1819084 [3]跟我一起写 Makefile,http://blog.csdn.net/haoel/article/details/2886
Published:
15 Apr 2012
离乡情怯
春节假期结束了,火车行驶了四十几个小时,把我从寒冷的西北又带到了温暖的南方,从家带向了学校。
下了火车,用了半个小时才买到广州地铁的车票,我背着装满厚衣服的书包,拎着箱子挤进了车厢。背上的书包不时碰到别人,我一边道歉一边取下包,站稳了位置。这时后边有人推我,我知道他要往前走,让出一个位置。一对年纪六十上下的大叔大妈提着大包小包挤了过去,车座上的人连忙让座,他们坐了下来放置好行李。
大叔出了一头的汗,站着的乘客好心,递给他几张纸巾,他接过来擦拭额头上的汗水,同时感叹广州已经有些热的天气,给他纸巾的大姐用广式普通话应答着。我欣慰于广州市民的热情,联想起北京有些公交上售票员对扛着行李的外地人的态度。
终于喘了口气,老两口感叹着进地铁的不易,大约是过验票口时遇到了点困难。
我打量着他们,头发白了一多半,身体还健康,看穿着应该是从小地方来的。他们带着三个捆扎起来的纸箱和两个包,我根据箱包的大小排列组合了几次才得到两个老人提这几件行李的方式。
想必箱子里都是家乡的土特产,而他们应该是来看儿女的吧。
他们的儿女为什么不来接站呢?哪怕上班也要请假来啊,从过惯了的家乡到大城市并不是件容易的事,对两个老人。
我想着他们的儿女,突然想起了我的父母。想起出门前,我对父亲说,爸,我走了;想起在汽车站,我对母亲说,妈,再见。
泪水在眼眶里打转,我赶紧假装是空调的风吹到了脸,一边扭头一边庆幸没人注意到我的窘境。
离开家时似乎坚强,到了这里却开始思乡。
地铁到终点站了,老人家拿好行李,我也重新背起包,各自汇入了城市滚滚的人流中。
Published:
21 Feb 2012
Book note:《我是沃兹》
父亲告诉我的方式是:不要死记硬背零件如何形成电路,而是理解电子流动在哪里才形成有用的电路;不要仅仅阅读线路图或是书上的内容,而要真正心领神会。
因为我已是成年人,有我自己的道德观——深刻关注人民的生活疾苦。我开始寻找生活真谛——如今我仍在这样做——我行事做人只为自己和他人拥有一个快乐的人生。
对政府行为,我所感受的震惊和恶心非笔墨所能形容:他们将我们的人生玩弄于股掌之间,并非如父亲所说,他们关心民众疾苦。
我具有幽默感,对生活我也保持这样的态度,只有快乐会成为我的选择。我认为是否快乐,取决于自己,只是自己。
我相当清楚自己要成为一位设计电脑的工程师,一位编写软件的工程师,一位风趣的工程师,一位愿意教授他人的工程师。
我清楚自己从不想玩社交游戏。即使到22岁,我也如此肯定自己并不想从工程领域调至管理层。我不愿进入管理层,进行政治性的争斗,或是踩着别人的肩膀往上爬。
大多上白班的人都喜欢在回家做些完全不同的事情。有些喜欢在家看电视,但我则喜欢做电子工程。我热衷于此,并以此为乐。
在我心中,道德举足轻重,至今我仍不能真正明白他为何对我撒谎。但是,大家都知道任何人是不同的。
在我心中,欢笑的人生远比掌握管理权重要得多,不过这只是我的观点。我认为快乐是人生中最重要的事,这样的人似乎有点傻傻的,但却是快乐的,这就是我一直以来想要成为的人。
这也是我为何从不会将《突出重围》事件放在心上的原因。即使你不赞同,甚至认为我们的关系出现裂痕,也不必认为我们相互为敌,只是性格不同罢了,而这就是快乐生活的最好方法。
我认为,人们对功能由许多需求,我们不应该限制人们的期望。
因为创建苹果公司,所以我能得到比维持生存更多的钱。我一生中从未打算赚一笔很大的钱。我常被那些为了在生活中创造更多事物的人们的故事所激励。
我记得我父亲那时告诉我,是教育能让我们提升到在生命中想要的高度,也能提升人的价值。
无论到哪儿,我都十分关注孩子——婴儿、幼儿、小孩子、大孩子。我试着跟他们交流,向他们微笑,给他们讲笑话,成为他们的玩伴。我自幼就被灌输这样一个想法:有”坏人”会伤害或绑架孩子,所以我决定成为一个”好人”,任何一个遇到的孩子都可以依靠的”好人”。
我喜欢小孩子们看着我的脸——简直是热爱。 我愿意给像我当时那样的年轻人有价值的建议,那些认为自己”格格不入”的、内心热爱设计和发明以及制造的年轻人,从而改变人们做事的方法。
当你发现你渴望实现你脑子里的主意时,我的建议就是关于这时你该做些什么的。你年轻、没钱,拥有的就是你脑子里的东西。你认为你脑子里的想法是好东西。这些想法就是你成天思考的东西,它们驱动着你。
但是,想发明些东西,与真正发明些东西,仍大有不同。比如,你怎么做这个,你怎样改变这个世界?
第一,你需要相信你自己,不要动摇。
有一些人——我提到的大多数人,尤其是你将要遇到的那些人的思维,通常都是非黑即白型。许多人看事情是从媒体或他们朋友看问题的角度来看的,如果他 们觉得媒体或朋友的观点是正确的话,那么其他人的观点就是错误的。所以,一个新想法——革命性的新产品或产品功能不会被许多人理解,因为他们看问题是用极 其简单的二分法。他们无法理解某样东西,可能是因为他们无法想象它,或者别人已经告诉他们什么是有用的或好的,而在他们听见的这些东西里面,并不曾包括你 的想法。
不要让这些人打消你的积极性。记住,他们只是用符合当时大众文化标准的观点来看问题。他们只看到了那些摆在他们面前的东西。这是种偏见,确切的说,这是一种绝对阻碍发明精神的偏见。
但这个世界不是黑白二分这么简单,中间还有许多灰色过渡。作为一个发明者,你必须看到事情的灰色过渡层次。你应当思想开明,不要人云亦云,根本不要 管大众的想法。你要保持客观,忘记自己听到的各种观点,清扫桌面,像一个科学家那样做实际的研究。你不要想一蹴而就,很快得出结论,然后尽可能地找论据来 证明自己的观点。谁会浪费时间支持一个糟糕的想法呢?顽固地坚持己见是不值得的,不要为此找任何理由。
得到能改变世界的新主意的唯一途径是,跳出现有的其他人的思维局限。你必须跳出其他人已经设置的人为障碍。如果你想想出别人以前从没想过的主意,你就得认识到一个有灰色层次过渡的世界,而不是只生活在黑白两色世界里。
为什么我说工程师像艺术家?工程师经常努力把事情做得更完美,甚至超乎他们的设想。……我们不停的加添代码,像一个画家用笔刷加添色彩,一个作曲家 加添音符。这就是到达完美的途径——努力使每件事完美地组合在一起,以一种前人未曾做过的方式。这使得工程师或其他人成为真正的艺术家。
在我一生中,我看到在每20位工程师中,才有一位能体现这种艺术家完美主义的人。所以让你的工程师工作成为艺术,是一件鲜见的过程,但这是我们应该努力达到的境界。我最近被电影《一往无前》(Walk the Line)所感动。在电影里,制作人告诉约翰尼·卡什,要带着”这首歌能拯救全世界”这样的想法来演奏它。
这总结了我在讨论设计和其他事物中的艺术时追求的许多东西。
如果你是那种罕见的工程师,兼具发明者和艺术家的素质,我将给你一些也许实现起来很难的建议:单独工作。
当你当家做主,决定自己要创造什么、如何去创造、如何协调功能和质量时,它就是你自己的一部分,就像一个你深爱着的孩子,想抚养他成长。你有巨大的动力创造最好的可能的发明——你以一种热情关心着它们,一种其他人命令你创造什么发明时不可能有的热情。
我现在十分自豪。我十分自豪。不仅仅是因为苹果翻身了,还因为它是以一种符合我们早期价值观的方式翻身的。那些价值观包括产品设计如何达到卓越,卓越到人们都对这个产品垂涎三尺。这种价值观也是关于情感的,一种愉快的情感。
如果你像我这么幸运,你将生活在这样一个时代:一次革新即将开始,而你正当年少。如同亨利·福特与汽车产业,我与第一台个人电脑。
我希望你也像我一样幸运。这个世界需要发明者——好的发明者。你可以成为这样的人。如果你热爱你做的事,愿意付出相应的劳动,你将终有所得。你在夜里独自工作,反复思考你想设计与制造的东西,为之花费的每一分钟都是值得的。
我敢肯定的告诉你,你的付出是值得的。
Published:
05 Jan 2012
