合并排序(merge sort)是利用分治法(divede-and-conquer)进行排序的方法,即将一个较大问题分解为n个规模较小而结构相似的问题,分别处理这些子问题然后将结果合并。合并排序将待排序的元素分成两部分,对每部分进行合并排序后,将两个分别有序的字部分合并起来成为一个有序结果。
下面算法中,mergeSort(int[] A, int p, int r)对数组A[p, r]进行排序,将问题分解递归处理,当待排序元素分解为只有一个时视为已经排好序;merge(int[] A, int p, int q, int r)将排好序的两部分元素进行合并,把已经排好序的A[p, q]和A[q+1, r]合并成按序排列的A[p, r]。
[code lang=”java”]public class MergeSort{
public static int[] merge(int[] A, int p, int q, int r){
int n1 = q - p + 1;
int n2 = r - q;
int[] L = new int[n1 + 1];
int[] R = new int[n2 + 1];
for(int i = 0; i < n1; i++){
L[i] = A[p + i];
}
for(int j = 0; j < n2; j++){
R[j] = A[q + j + 1];
}
L[n1] = Integer.MAX_VALUE;
R[n2] = Integer.MAX_VALUE;
int i = 0, j = 0;
for(int k = p; k <= r; k++){
if(L[i] < R[j]){
A[k] = L[i];
i++;
}else{
A[k] = R[j];
j++;
}
}
return A;
}
public static int[] mergeSort(int[] A, int p, int r){
if(p >= r){
return A;
}
else{
//如果数据类型非整型,q要向下取整
int q = (p + r) / 2;
A = mergeSort(A, p, q);
A = mergeSort(A, q + 1, r);
A = merge(A, p, q, r);
return A;
}
}
public static void main(String[] args){
int[] array = {3, 2, 6, 1, 9, 7, 8, 5, 4};
for(int i : array){
System.out.print(i + ",");
}
System.out.print("\n");
array = mergeSort(array, 0, array.length - 1);
for(int i : array){
System.out.print(i + ",");
}
} } [/code]
利用递归式和递归树可以证明,合并排序的时间复杂度是O(nlgn)。(见《算法导论》P21)
Published:
14 Aug 2011
插入排序(InsertionSort)是一个对少量元素进行排序的有效算法,它的基本思想和打牌时整理牌的顺序方法类似:如果右手中有一组需要按照大小排序的牌,则依次从中取出一张牌放入左手,每次新取出的牌按照大小关系插入到左手牌中合适的位置,直到所有的牌都排序完成,因此称之为插入排序。
插入排序的Java代码如下所示:
[code lang=”java”]public class InsertionSort{
public static int[] sort(int[] array){
for(int i = 1; i < array.length; i++){
int key = array[i];
int j = i - 1;
while(j >= 0 & array[j] > key) {
array[j+1] = array[j];
j–;
}
array[j+1] = key;
}
return array;
}
public static void main(String[] args){
int[] array = {3, 2, 6, 1, 9, 7, 8, 5, 4};
for(int i : array){
System.out.print(i + ",");
}
System.out.print("\n");
array = sort(array);
for(int i : array){
System.out.print(i + ",");
}
} }[/code]
在最优情况下,即待排序数的顺序已经排好,则上面算法中,插入部分(while循环)不需要进行,插入排序的算法复杂度是O(n);在最坏情况下,待排序数是逆序的,插入部分需要进行最多次,则算法复杂度是O(n^2)。
总结:插入排序对部分有序的数据是极好的排序算法,对小型数据也是较好的排序方法。
Published:
13 Aug 2011
分词是文本处理、分析的基础,中科院分词系统ICTCLAS是中文领域中功能强大的分词系统。下面介绍如何在一般的Java程序和Lucene中使用ICTCLAS。
首先在ICTCLAS官方网站下载分词系统源码,地址是http://ictclas.org/ictclas_download.aspx,目前的版本如下图所示:
根据操作系统和编程语言的需要选择下载,本文使用的是ICTCLAS2011_Windows_32_jni版本。
将下载文件解压后,有四个文件夹:
其中,API中是完整的软件包,可以调用其中的函数实现分词功能;Demo是使用图形化界面演示分词效果的程序;Doc是软件文档;Sample是一个Java中调用ICTCLAS的例子。
1.一般Java程序
一般Java程序使用中科院分词系统ICTCLAS参考Sample文件夹中的示例程序即可。
示例程序TestMain.java的主要内容如下:
[code lang=”java”]class TestMain
{ //主函数
public static void main(String[] args)
{
try
{
//字符串分词
String sInput = "随后温总理就离开了舟曲县城,预计温总理今天下午就回到北京。以上就是今天上午的最新动态";
testICTCLAS_ParagraphProcess(sInput);//同testimportuserdict和testSetPOSmap
}
catch (Exception ex)
{
}
}
public static void testICTCLAS_ParagraphProcess(String sInput)
{
try
{
ICTCLAS50 testICTCLAS50 = new ICTCLAS50();
String argu = ".";
//初始化
if (testICTCLAS50.ICTCLAS_Init(argu.getBytes("GB2312")) == false)
{
System.out.println("Init Fail!");
return;
}
//设置词性标注集(0 计算所二级标注集,1 计算所一级标注集,2 北大二级标注集,3 北大一级标注集)
testICTCLAS50.ICTCLAS_SetPOSmap(2);
//导入用户词典前分词
byte nativeBytes[] = testICTCLAS50.ICTCLAS_ParagraphProcess(sInput.getBytes("GB2312"), 0, 1);//分词处理
System.out.println(nativeBytes.length);
String nativeStr = new String(nativeBytes, 0, nativeBytes.length, "GB2312");
System.out.println("未导入用户词典的分词结果: " + nativeStr);//打印结果
//导入用户字典
int nCount = 0;
String usrdir = "userdict.txt"; //用户字典路径
byte[] usrdirb = usrdir.getBytes();//将string转化为byte类型
//导入用户字典,返回导入用户词语个数第一个参数为用户字典路径,第二个参数为用户字典的编码类型
nCount = testICTCLAS50.ICTCLAS_ImportUserDictFile(usrdirb, 0);
System.out.println("导入用户词个数" + nCount);
nCount = 0;
//导入用户字典后再分词
byte nativeBytes1[] = testICTCLAS50.ICTCLAS_ParagraphProcess(sInput.getBytes("GB2312"), 2, 0);
System.out.println(nativeBytes1.length);
String nativeStr1 = new String(nativeBytes1, 0, nativeBytes1.length, "GB2312");
System.out.println("导入用户词典后的分词结果: " + nativeStr1);
//保存用户字典
testICTCLAS50.ICTCLAS_SaveTheUsrDic();
//释放分词组件资源
testICTCLAS50.ICTCLAS_Exit();
}
catch (Exception ex)
{
}
} } [/code]
编译、运行此程序,分词结果如下。

其中,分词的词性标注是可选的,词性标注的含义在Doc目录下的文档中有详细说明。
2.Lucene
在Lucene中起到文本分析作用的类是Analyzer,Lucene中自带的不同Analyzer子类具有不同的分词功能。在较新的Lucene版本中(我使用的是3.0.3),Lucene自带的smartChineseAnalyzer是基于中科院分词系统实现的,中文分词效果比较好,已经能满足一般的中文分词需要。但是它不具备ICTCLAS原有的词性标注功能,如果想使用ICTCLAS的完整功能,则需要基于ICTCLAS编写自己的Analyzer子类。
ICTCLAS官网上有一个编写Analyzer子类的程序示例,地址如下:
给Lucene加入性能更好的中文分词
另外,我的同学cjy写了一个更为完整的Analyzer子类,可以参考,源代码下载地址为:
将中科院分词系统ICTCLAS应用到Lucene中的Analyzer源代码
Published:
08 Aug 2011
相比睡前上网和看电影,我还是更喜欢捧一本书读上半小时。看的书种类不定,但这一段时间我突然体会到,每天最后时刻要读的不应该再是功利性质的书,在这珍贵的时间里,应该读一读能让人安静下来,思考和领悟更接近人生本质的东西。关于时间,生死,回忆,宇宙,自我……大概思考这类终极的问题时人最容易抛弃日间凡事的纷扰,心中想着这些,并没有对过去的追悔,对现在的焦虑,对未来的担忧。也会抛弃了种种自傲自卑的心理,虚伪荒诞的想法。这种静静的状态对着电脑屏幕是得不到的——那只会让你更浮躁。不需要总结什么,计划什么,体会到那种单纯的状态,会觉得一切都是美好的。
近来读的两本书都很符合我的要求,《预约死亡》和《灵魂只能独行》。
睡前读书的那段时光,是每一天最好的结束。
PS:上面的这些文字写于两个月前,现在读来,觉得追求宁静固然是养心的好方法,然而”抛弃日间凡事的纷扰”只是暂时忘记了而已,如果不能真的把道理想通、把事情解决,这些问题迟早会浮现,那时宁静也就无从寻找了。毕竟只有佛才通过顿悟抛弃了烦恼,凡夫俗子终究要面对现实生活。所以,在执着和超脱,世事和宁静间寻求平衡才更应该追求。
Published:
06 Aug 2011
为了复习Lucene,今晚读了Lucene in Action英文第二版的第一章。发现读英文技术书并没有我想的那么困难,以前因为效率原因总是优先选择读翻译的内容,因为这个第二版还没有中文版本,转读原版,竟然读出点感觉来。
这里翻译部分书中内容,总结Lucene里重要的类,即书中第一章的主要内容。这些类是整个Lucene的基础。
核心类包括索引类和搜索类。
核心索引类
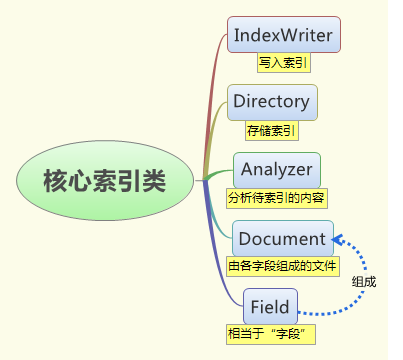
IndexWriter-一个对象,可以使你写入索引但是不能读或者搜索索引。它把索引存在Directory中。
Directory:存放索引的地方。IndexWriter只能索引分成单个词的文本——使用analyzer。
Analyzer:负责从文本抽取词项的抽象类;去掉停用词;转换大小写……。分析过程需要一个文件,它包含了各个需要被索引的域。
Document:一个域的集合。
Field:域Field是一个保存需要索引的文本内容的类,由名称和对应值,一些选项组成。
核心搜索类
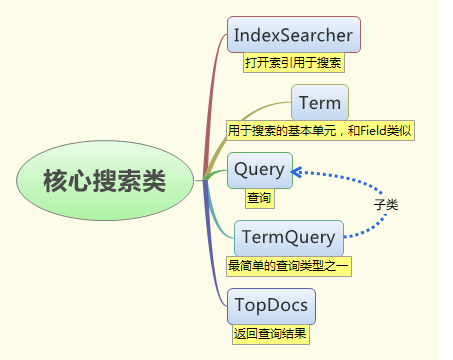
IndexSearcher:是一个将索引以只读模式打开的类。提供一些搜索方法。
Term:用于搜索的基本单元。和field类似,包含一个域的名称和域的文本内容。在搜索时,组合Term对象以和TermQuery一起使用。
Query:Lucene有一些具体的Query子类,它提供一些使用的方法,如setBoost。TermQuery是复杂查询的组成构件。
TermQuery:Query的子类,最简单的查询类型之一,用于匹配包含具有制定值的域的文件。
TopDocs:是包含排名最前的N个搜索结果指针的容器。存储了文件编号和分数值。
Published:
07 Jul 2011
读那些反映改革开放历史的书总能让人有种历史激荡、心潮澎湃的感觉,《平凡的世界》、《大江东去》都畅快淋漓的描写了打破僵化体制、用努力改变命运的故事,显示出一种旺盛勃发的生命力。吴晓波的《激荡三十年》回顾了这段历史中的中国企业,相比小说,这本书更富有学术和历史的观点,却也不乏生动的故事和人物。正如央视纪录片《公司的力量》所强调的,”你能看到多远的过去,就能看到多远的未来”,这本书不仅是在梳理过去,同样能帮助我们理解当今和未来的中国。
简单地记录我的几点困惑和感想:
一、产权问题
三十年企业史中,产权一直困扰着许多企业,这也是本书一直在论述的问题,但我还是没有深刻的理解它。上学期的一门政治课上,老师在最后时间也谈到了这个问题,由于时间所限没有展开分析,令人遗憾。从他的只言片语感觉到,产权问题牵涉了太多的复杂利益,我们所看到的可能只是表象。也许要进一步理解,需要从理论基础和现实问题两方面入手,并不简单。产权看上去是个理论问题,然而现实中,许多事情的根源正来自于此。
二、互联网企业
令我意外的是,作者对互联网企业有着独特的评价。吴晓波认为,如果中国能诞生真正伟大的企业,互联网是最有希望的行业。除此之外,另一个观点也让人印象深刻:
"在中国进行了15年的变革之后,世界把他的左脚踏进了互联网的河流之中,在这个意义上,中国是幸运的。"
互联网并不只是一种通信技术,它所影响的太多。
三、该学习什么?
走马观花的通读了全书,感到自己的知识储备还是薄弱。除了上面的产权,与证券相关的事件、税制问题等读完也只能说是略知一二。不谋全局,不足以谋一域,我一直觉得要想更多的了解世界和自己的国家,了解社会的发展规律,需要从原理层面去学习和思考,不能总是就事论事,在纷繁的现象层面停留。不过说到对这些问题的学习,该读些什么,本身就是个问题,因为在你有足够深刻的洞察力之前不容易知道哪些观点是相对客观,哪些观点带有自身目的。交些学费大概是免不了的吧。
后记:
读完后本来不想写评论,因为自己并没有新鲜的、有价值的观点。就像上面写的,问题更多一些。不过我还是不要太追求完美——这样容易使人畏难而不断拖延。先把第一感受记录下来,以后倘有机会再完善。
不要忌惮于暴露自己某些时候、某些方面的无知与浅薄,这可能是进步的源头。因为追求完美而选择拖延,不如降低要求,开始再说。
对这三十年感兴趣的读者,可以把此书和《大江东去》对照阅读,能对历史有多角度的了解。
Published:
04 May 2011
使用Lucene自带的示例程序lucene-demos-3.0.3.jar时,发现其中的索引程序IndexHTML.java索引一些网页时会报错:
Parse Aborted: Lexical error at line 63, column 16.
Encountered: "\u987b" (39035), after : ""
出错的地方都是HTML标签中Unicode编码的中文字符处。
经过一些搜索和试验,解决办法如下:
1. (见http://www.wenhq.com/article/view_448.html )
第一:先下载一个javacc
第二:修改HtmlParser.jj文件的
options { IGNORE_CASE = true; STATIC = false;} 为:
options { IGNORE_CASE = true; STATIC = false; UNICODE_INPUT=true;}
第三:运行javacc HtmlParser.jj
第四:把产生出来的java文件覆盖JavaCC HTML Parser 的源文件
除了修改HtmlParse.jj外,还做了如下两处修改:
2.(见http://blog.eood.cn/lucene%E5%A6%82%E4%BD%95%E7%B4%A2%E5%BC%95utf-8%E6%A0%BC%E5%BC%8F%E6%96%87%E4%BB%B6)
在IndexHtml.java文件中,
HTMLParser parser = new HTMLParser(fis);
改为:
HTMLParser parser = new HTMLParser(fis,"utf-8");
3.修改HTMLParser.java。
public Reader getReader() throws IOException {}中,
pipeIn = new InputStreamReader(pipeInStream, "UTF-16BE");
pipeOut = new OutputStreamWriter(pipeOutStream, "UTF-16BE");
将上面两行原来的编码都换为UTF-8。
完成上面的修改后,把java文件都编译为class文件,重新打包。
注意打包时,应该切换到/demo路径下,即此时在文件夹窗口可以看到的应该是org文件夹。
打包命令是:
jar cvf lucene-demos-3.0.3.jar org
完成上述修改后就可以使用新的jar包进行文件索引操作。
Published:
26 Apr 2011
最近我上人人网的时间已经严重缩水了,相比以前每天刷屏几次,现在一天也不一定登录一次。除了微博的替代作用外,我想更多的还是人人自身的问题。
对我而言,上人人网有两个目的,一是和现实中的朋友交流,了解他们的"新鲜事",作为人际交往的扩展;二是,随机寻找一些有益或者有趣的高质量内容,由于人人网好友的背景相似,往往他们分享的内容对我也有用处。(最近在学校校庆期间,我登录人人的时间又增加了,因为从同学发布的新鲜事里我总能找到正式媒体上看不到的新闻。社交媒体的作用可见一斑。)
然而,这两个目的越来越难以实现了。第一条,交流目的,现在每天的新鲜事里,基本都是师弟师妹们的声音,和我同级或是更高年级乃至工作了的好友,基本不再在这里频繁发声。交流已经不能像以前一样。第二条,高质量内容,这更是让人遗憾,以前看一遍新鲜事,总能有一些内容让我有分享、收藏、评论的冲动,然而今年以来,常常是一无所获。看到的内容,总是各种碎碎念……
两个吸引我的动机都不能满足,自然没有动力在人人上消磨时间。想想以前发了日志和照片等人评论的时光,大概已是明日黄花了。
第一个问题,是人人网的用户年龄段所限吗?我没有数据,只能直观感觉,我的好友,只要是工作了的,在人人上出没的概率就大大降低。我想,对刚工作的新人而言,在职场中建立新的人际关系更重要,而这些人际关系如果能出现在网络上,几乎不太可能是在人人网,相比之下,微博似乎是个更好的选择。就兴趣来说,人人上,他们更容易看到的还是校园内的新鲜事,这些事件的吸引力不如职场事件,可能因此减少了使用时间。
第二个问题,关于用户生成内容(UGC)。以UGC为核心的网站,鼓励用户产生有价值的内容绝对重要。虽然人人是基于人际关系的网络,和人际关系有关的内容(比如上面说的各种碎碎念)必然占据重要的地位,但是,社交网络之所以被认为可以挑战搜索引擎的地位,正是因为它构建了信息传播的新渠道,在人际关系之外,满足用户兴趣需要的内容同样重要。在微博上,你可以关注任何能提供这类内容的人,他们源源不断的贡献这种内容,你的评论、转发和他们形成了良好的互动。人人上,这类高质量信息源较少,也没有鼓励机制,优质内容越来越少。
对我这样的人人用户来说,增加符合个人兴趣的推荐系统,可以在很大程度上提高我的使用黏度。只是,在人人看来,它的典型用户会是谁呢?
曾经让我着迷的人人,会重新吸引我的目光吗?
Published:
23 Apr 2011
